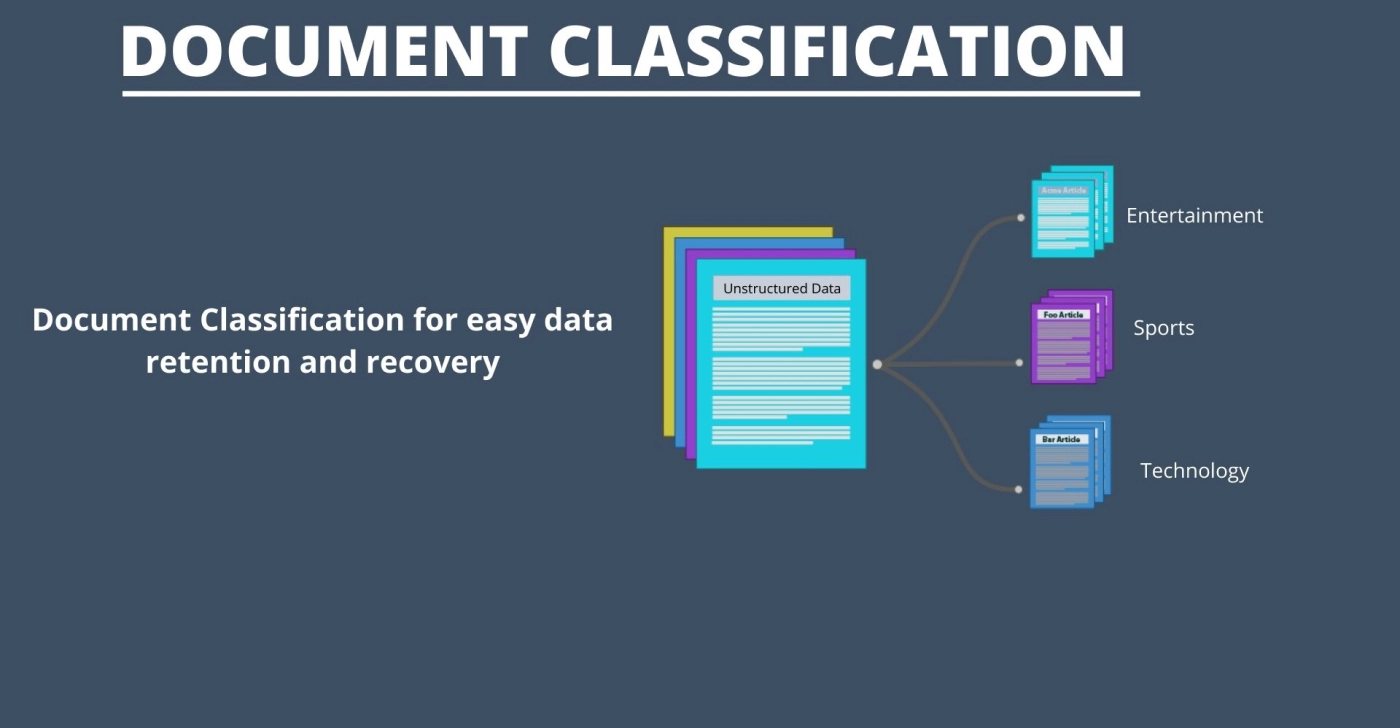
About the client:
The Client is a US-based organization, working in the Knowledge management area. They also have good work going in Machine learning and have some really good solutions around it.
Challenges :
The clients are working in the content management area and need to process a huge number of documents. They need to classify these number of the document manually and store those documents in AWS bucket which require additional efforts.
Following were some of the challenges the client faced :
- Data Retention and Recovery.
- Usability of existing data.
- Content Security and Digital Rights management.
- Enterprise search and Analytics.
- Existing Content Management System Enhancements.
- Globalization: As the Knowledge Management industry operates globally they need to expose their content globally.
Our Solution:
To overcome these efforts, LogiQuad suggested building an automated system that classifies the document and stores that document in the AWS bucket under the specified category.
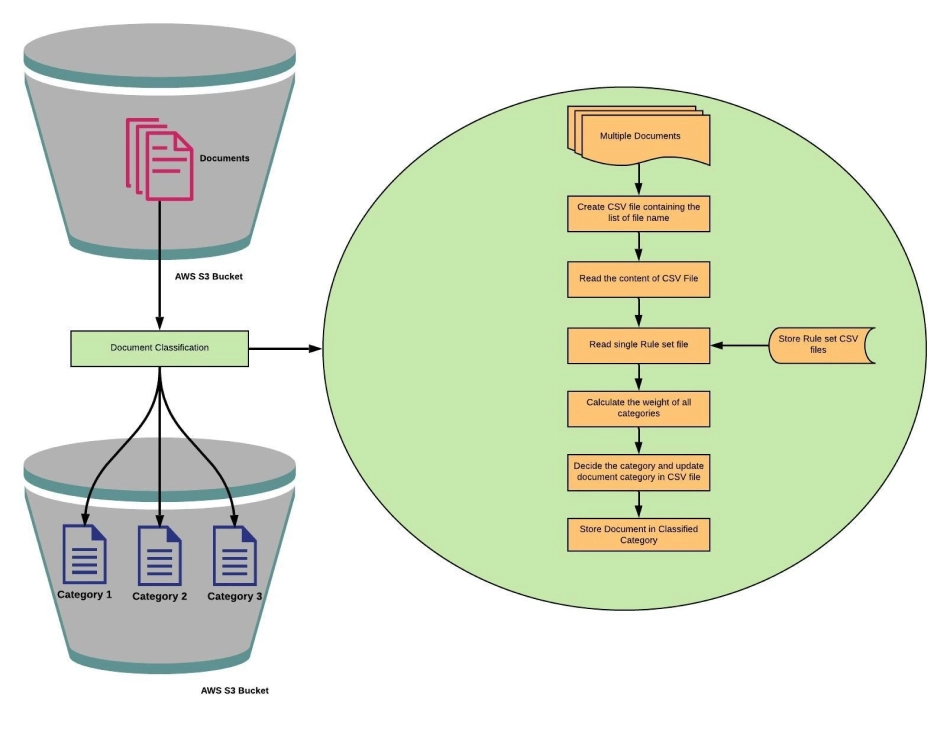
To provide a solution to this problem, our team studied the provided sample files for each category and created rule files. Rules are CSV files containing word phrases with some weight for each word phrase.
- The files are stored in the S3 bucket. We are using two lambda functions. One Lambda function read the files name from provided S3 buckets and created a CSV file with the name of files stored into that bucket. To execute this function, we have created a crone job that executes this function after some time of interval.
- Another lambda function is used for processing that files using provided ruleset and decides the category of that document. The document is processed for all provided ruleset. The category with the highest weight is the category of that document.
- Then that document is stored under that category folder and the category is updated into created CSV file.
To design this system, we are using two lambda functions and an S3 bucket to store those classified files. You need to provide the below configuration for this application.
- S3 bucket access key.
- AWS S3 bucket name where all unclassified files are stored.
- AWS S3 bucket name where classified files are stored.
- Your Ruleset files (in CSV format).
Architecture:
Business Benefits/Outcome:
This system overcomes the manual efforts needed to classify the documents, store them back in the S3 bucket and show the user what kind of data they have. LogiQuad helped in achieving the following business outcome for the client.
- Helped in Increasing throughput/productivity by 45%
- Helped in saving man-hours, eventually leading to significant cost reduction.
- The cycle time of Installations reduced drastically in operations.
- Tasks are completed at a high degree of accuracy as the process is now system dependant
- reducing human error.
- Reduces operation time and work handling time significantly.
- Frees up employee’s time to focus on other roles.







